
So far, I've shown that Strava's Privacy Zones can be reverse-engineered in a city. And that you only need a few activities to do this. While a larger privacy zone helps, it's still not the force field many might hope for.
But what happens outside cities? Many people live in other locations and exercise in the countryside or suburbs: some run on quiet rural lanes, others start from farm tracks and plenty live on cul-de-sacs or scattered suburban streets. These different environments could make Privacy Zones much stronger... or weaker.
In this post, I'll explore how well Strava's Privacy Zones hold up in other places - and whether the change of scenery actually helps protect you.
Different Locations (City vs City Grid vs Rural vs Cul-de-sac)
Setup
In my first three posts, all my testing happened in an "irregular" city environment (London), which has a fairly chaotic street layout with a healthy mix of straight roads, bendy roads, angled junctions, a park to one corner, and so on, which created a naturally wide distribution of possible ways to head out from home. That distribution is a key ingredient when trying to reverse-engineer a privacy zone: the more directions your activities can fan out from home, the more clues any method has to work with.
But what happens when the underlying geography changes?
To test this properly, I explored three new environments, each with a distinct pattern of "ways you can leave home":
-
City Grid - a rigid, orthogonal street network with right angles and evenly spaced blocks. It's the opposite extreme of the irregular city (in a dense city context): plenty of exit options, but arranged with much more regularity.
-
Rural Location - very few roads, very few decision points and typically only a few viable ways to begin an activity.
-
Cul-de-sac - the most constrained case of all. A single road in and out, meaning every activity shares the same first several hundred metres. There's essentially no distribution at all, just one path in and the same path out, repeated across every activity.
Route Generation
To keep the environments comparable, all routes followed the same general framework as in post 1. However, two refinements were added to make the synthetic activities behave more like real-world activities.
First, each activity can begin with one of several predefined starter routes, short GPX snippets manually defined that mimic the familiar ways people repeatedly leave home.
Second, each waypoint receives a small GPX jitter, adding the sort of variation real GPS traces often contain and preventing multiple routes from lying perfectly on top of each other in the visualisations.
These refinements only applied to the rural and cul-de-sac environments, where the limited number of natural starting options made the synthetic data look too uniform without them.
With those refinements in place, each environment used:
-
40 synthetic routes (the same as before) - enough variety to reveal patterns without cluttering the map.
-
Starter routes - for rural and cul-de-sac only: a randomly selected short GPX snippet is prepended to each activity to mimic how people typically leave home from that location.
-
GPX waypoint jitter - for rural and cul-de-sac only: tiny random offsets simulate real GPS noise and prevent traces from perfectly overlapping in the visualisations.
-
Upload → Privacy Zone applied → Download - every route was uploaded to Strava, the privacy zone applied by Strava and the privacy-processed versions were downloaded for analysis. All results are based on these processed activities.
City Grid
Routes
Here's what the 40 generated routes look like in the city grid environment, well distributed but this time as neat orthogonal paths.
After uploading and letting Strava apply a 200m privacy zone, the starter points collapse into the familiar circular shape, just like in the first post and again far fewer than 40 distinct routes. Nobody leaves their house 40 different ways!
Time to see how the reverse-engineering methods perform.
Results
The predictions land very close to the true start location, very similar to the irregular city results. The best method comes in at 29.1m, almost identical to before and most methods settle around ~40 m. Performance is a fraction worse, just a few metres, but well within the same overall bracket.
All predictions skew slightly west. This becomes obvious once you inspect the starter point cluster: the eastern points sit closer to the true location, so any geometric method that draws circles or polygons around all points ends up nudging the calculated centre westward.
Let's break down a few specific methods.
Boundary Method
This is the top performer. The predicted point lands 29.1m from the true start.
You can see the polygon including all the start points, giving it a well-balanced centre.
Circle Fit Method
The Circle Fit Method holds up reasonably well too, at 46.4m.
The westward pull is very clear here: the method treats the easternmost points as outliers and trims them away, leaving the remaining circles biased west. An attacker could easily correct for that by manually re-centering the circles.
Donut Overlap Method
The Donut Overlap Method heatmap produces a tight, well-defined hotspot, with the true start sitting right on the edge of it.
The "hot" region is slightly offset, which explains the prediction of 43.9 m. Not perfect, but still a reasonable prediction.
Adaptive Donuts Method
The Adaptive Donuts Method performs slightly better: the hotspot is broader and captures the true start location clearly.
That extra spread helps narrow the prediction a little, bringing it to 41.6m.
Overall, the city-grid environment behaves almost identically to the original city environment. Most predictions land around ~40m and the best method hits just under 30m, virtually the same as before. The only real difference is a small, consistent westward bias caused by how the starter points happen to cluster.
Rural
Routes
Rural environments are a very different beast. There are only a handful of roads, often no early junctions and crucially, most activities begin in a few directions simply because there aren't other options. And that scarcity of options is exactly what makes rural environments a different challenge to reverse-engineer: the geometry offers far less to work with.
For this test, I picked a location with four plausible starter options, although three of them share the same initial 1.5 km before diverging. To reflect that structure, I manually defined four starter routes and added a touch of GPX jitter to each one. Without that jitter, every GPX file would lie perfectly on top of the next, which is unrealistic.
Here are the 40 generated routes, all leaving home in two key directions - the only way out from this location.
After generating the activities, everything followed the standard workflow: Upload → let Strava apply a 200m Privacy Zone → download the privacy-processed versions.
Unlike a city, where start points typically form a ring around the privacy zone, this rural location simply can't produce that circular pattern. The road geometry forbids it. Instead, the visible start points cluster into two tight groups, one on either side of the true start.
Clearly it's not difficult with this information to reverse-enginner and find the true start, visually it must lie roughly halfway between the two sets of points. This is a big red flag. This should be the first warning sign that privacy zones in the default setting on Strava (200m) are not appropriate for rural locations (or any location where there are two options from your home for the first few 100m's).
Results
Now let's try the reverse-engineering methods in this rural setting.
The results vary widely. Overall, they're noticeably worse than in a city.
The simple average method places the start location 127.6m away. Visually, it's clear why: the prediction is pulled west, where there are more initial route options. This highlights a limitation of the Simple Average Method in that it tends to bias toward directions with higher point density. A more refined approach could rebalance the contributions from each direction before averaging to improve accuracy.
The Circle Fit and Donut Overlap Methods perform poorly here as well. The more reliable performers are the Boundary and Adaptive Donuts Methods. Let's take a closer look at these individually to understand the story behind the results.
Boundary Method
The Boundary Method performs reasonably well, predicting the start location at 56.7m from the true point. Unsurprisingly, the polygon shape here looks very different from the city scenario: it forms a narrow, almost triangular structure around the three clusters of start points. The polygon's centre falls roughly midway between the two ends of this triangle, placing it close to the true start location and explaining why the prediction is relatively accurate.
Circle Fit Method
The Circle Fit Method performs very poorly here, predicting the start location 278.1m away. The reason is straightforward: the method tries to fit a single circle to the start points, but in this rural setting the points split into two clusters along different directions. With only two clusters, there are effectively infinitely many circles that could fit, making the method essentially useless. Constraining the circle radius could reduce the number of possible solutions, but even then it remains far from an ideal approach in rural settings.
This illustrates the core problem: two points define an infinite family of valid circles, offering no unique solution for the Circle Fit Method.
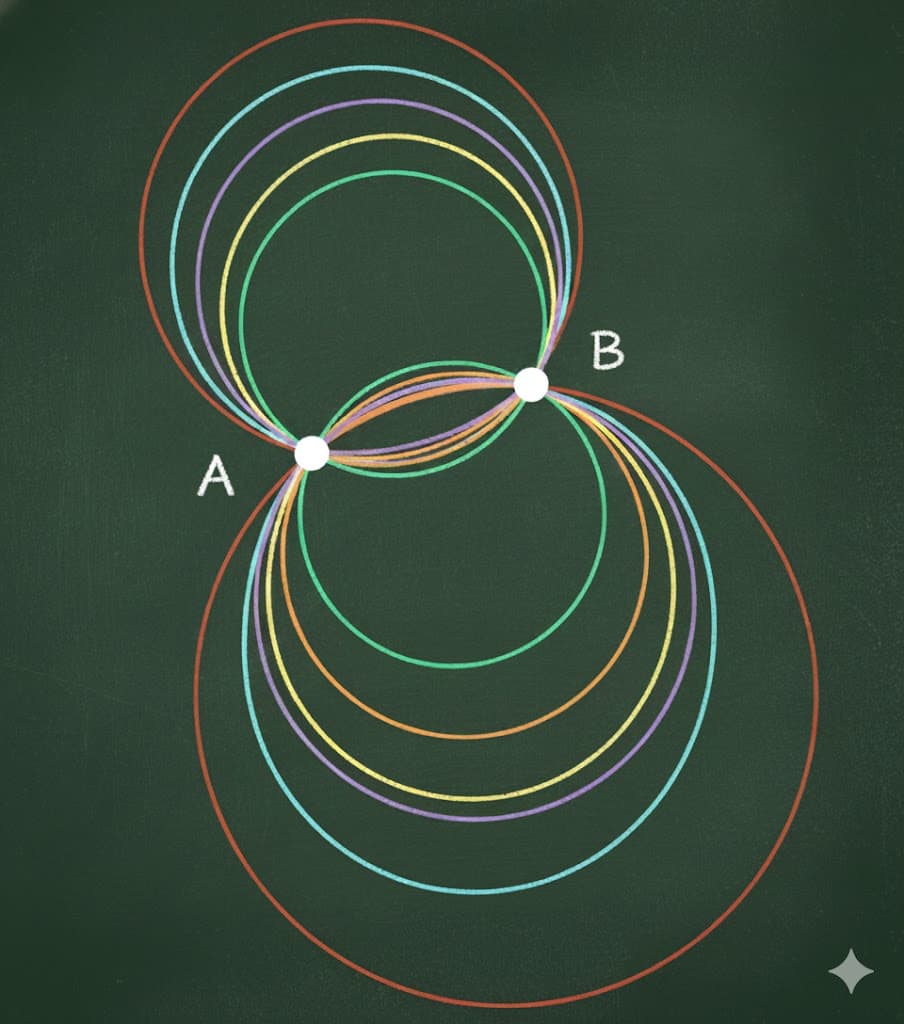
Two points define infinitely many possible circles.
Donut Overlap Method
The Donut Overlap Method also performs poorly here, predicting the start location 245.1m away. The heatmap clearly shows the difference in frequency of start points, with the left circle, containing more points, appearing much "hotter" than the right.
This result is not surprising, since the donuts radius depends on the Circle Fit Method - which, as we've seen, is wildly inaccurate in this rural setting. Here, the method generates two donuts, one around each cluster, producing two intersection regions. The outcome is highly sensitive to the chosen radius: too small and the circles don't intersect, too large and you get multiple intersections, as we see here. Ideally, a correct radius would produce a single intersection containing the true start, but determining that radius in practice is tricky.
The clustering algorithm then selects the "hotter" of the two intersections as the predicted start location, which given the incorrect radius, ends up far from the true start. In this case, the true location lies in the overlap between the donuts but outside their edges.
There are ways to improve this, by reducing the donuts radius gradually until a single overlap appears would help capture the true start. The Adaptive Donuts Method largely solves this issue though, as it does not rely on a single radius and instead uses metadata from Strava for more precise predictions.
Adaptive Donuts Method
The Adaptive Donuts Method performs the best, and the heatmap makes this immediately apparent. The "hot" zone shows a single, well-defined overlap, because the radii of the donuts vary based on Strava's overall distance rather than relying on a single fixed radius. The clustering algorithm identifies this overlap, producing a predicted start location just 42.4m from the true start. With further refinement, such as snapping to the nearest point on the road network, this distance could be reduced even more.
Overall, this method provides a highly accurate prediction, very close to the true start location.
Cul-de-sac
Routes
The rural scenario explored multiple starter directions, but what happens when there's only a single route out every time, like a cul-de-sac or a long driveway? This is the case I examine here.
Common-sense might suggest this should be easy to reverse-engineer, but in practice the geometric methods I've used so far are likely to be ineffective here. With every activity starting along the same initial path, the start points should collapse to more or less a single point. There's virtually no variation or distribution in these points, which means the methods have very little information to work with.
The cul-de-sac route is essentially a single long driveway, ~1km in length. To create variety, I defined 13 different starter routes, all beginning with the same driveway segment. Small random GPX jitter was added to each route to mimic real-world variation.
After uploading these to Strava and letting the privacy zones be applied, the processed start locations are pushed roughly 370m down the road.
Results
As expected, the geometric methods perform poorly in this cul-de-sac scenario. With all activities starting along the same driveway, the start points form a single, tightly clustered group with almost no variation. As a result, there's virtually no information for these methods to work with, and all essentially predict the same location.
This case is unique: the complete lack of distribution means no geometric method can improve on their crude estimates. In practice, there's a really simple and reliable way to determine the start visually - by just following the route in either direction from the start cluster, which in this instance is trivial given there is only one property at the end.
An improved methodology is required to handle such scenarios, which I will explore next time.
Overview
Reviewing the results across all methods and locations highlights some clear patterns.
- The Boundary and Adaptive Donuts Method are consistent and reasonably reliable, typically reverse-engineering the true start location to within ~40m.
- The average method performs well when points are well distributed, such as in a city, but struggles in rural settings where distribution is limited.
- The Circle Fit Method is particularly unreliable in sparse environments: with only a few clustered start points, there are effectively infinite circles that could fit, making predictions unstable.
- The Donut Overlap Method also struggles in these cases, since it depends on a fixed radius that is difficult to determine accurately with few points.
- By contrast, the Adaptive Donuts Method largely overcomes this limitation, adjusting radii dynamically and using metadata from Strava to improve predictions.
Location clearly matters. Geometric methods work best in cities, where start points fan out across multiple routes. Rural locations are more challenging, though not impossible, as the Adaptive Donuts Method demonstrates. When there is only a single start location, such as a long driveway or cul-de-sac, all geometric methods perform poorly, since there is no distribution of points to exploit.
| Method | City | City Grid | Rural | Cul-de-sac |
|---|---|---|---|---|
| Simple Average Method | 29.9m | 37.9m | 127.6m | 156.4m |
| Boundary Method | 37.4m | 29.1m | 56.7m | 157.6m |
| Circle Fit Method | 33.9m | 46.4m | 278.1m | 155.0m |
| Donut Overlap Method | 28.5m | 43.9m | 245.1m | 156.2m |
| Adaptive Donuts Method | 31.0m | 41.6m | 42.4m | 157.8m |
Scaling Up the Privacy Zones
Before wrapping up, it's worth stepping back to see how these methods scale as the privacy zone gets larger.
In my previous post Does a Larger Privacy Zone Protect You on Strava?, we saw a clear trend in the city location: doubling the privacy zone radius roughly doubles the prediction accuracy and even at 800m the best methods could still land within ~125m. Larger zones definitely help - but they're far from a perfect defense.
The results below expand that view to the city grid and rural locations.
City Grid
| Privacy Zone Radius | 200m | 400m | 800m |
|---|---|---|---|
| Simple Average Method | 37.9m | 72.1m | 79.8m |
| Boundary Method | 29.1m | 87.6m | 183.3m |
| Circle Fit Method | 46.4m | 100.3m | 182.9m |
| Donut Overlap Method | 43.9m | 96.3m | 118.7m |
| Adaptive Donuts Method | 41.6m | 77.2m | 169.7m |
The pattern is remarkably consistent with what we saw earlier: accuracy degrades steadily as the radius grows, with the effect most visible at 800m.
Across the city grid, the trend is clear and very much in line with what we saw previously: as the privacy zone radius grows, prediction accuracy rises in a steady, almost linear way. Interestingly, the Simple Average Method performs best here - the benefit of a clean, symmetric distribution - while the other methods track close behind, all still landing within broadly similar ranges. In short, the city remains the easiest environment for these geometric techniques, and increasing the privacy zone just stretches the same pattern we saw before.
Rural
| Privacy Zone Radius | 200m | 400m | 800m |
|---|---|---|---|
| Simple Average Method | 127.6m | 198.5m | 384.6m |
| Boundary Method | 56.7m | 94.7m | 200.3m |
| Circle Fit Method | 278.1m | 370.0m | 696.1m |
| Donut Overlap Method | 245.1m | 365.6m | 692.9m |
| Adaptive Donuts Method | 42.4m | 85.8m | 182.6m |
In rural settings, the pattern is similar but the gaps widen. The Adaptive Donuts Method remains the most reliable, scaling cleanly from ~42m at 200m to ~183m at 800m. The Boundary Method follows the same trend. By contrast, the Circle Fit Method and Donut Overlap Method fail for the reasons I've already discussed: with only two directional clusters, the circle fitting is ill-posed, and the Donut Overlap Method inherits that instability. The Simple Average Method struggles too, pulled toward the denser cluster, only roughly halving the privacy zone radius - something you could do by eye.
Cul-de-sac
For the cul-de-sac, there's nothing to really measure: with a single start path and no spread in points, all geometric methods fail. Changing the privacy zone radius therefore isn't a meaningful exercise at this point.
Summary
Overall, larger privacy zones do increase prediction distance across all locations, but the effect depends heavily on the underlying distribution of start points.
Wrapping Up - What This Means (And What's Next)
The results are clear: location matters. In cities, the best geometric methods reliably predict the start to within ~40m. In rural settings, sparse start points make some methods struggle, though a few still perform reasonably well. For cul-de-sacs or single-driveway starts, all geometric methods fail - there's simply no distribution to work with.
But don't think rural locations automatically protect your privacy. Visually, these routes are often trivial to reverse-engineer. In the next post An Advanced Method To Reverse-engineer Strava's Privacy Zones: Ringing the Doorbell, I'll dive into improved methods that leverage the road network - showing how even in sparse environments, it's possible to tighten predictions and get closer to the true start.